
The first series of Learning by Reversing examines a Ruby native gem to understand how it works. Part 7 examines how native code is documented.
Previously, in this series, we have had:
- Part 1 – Background to the gem we are looking at (including installing, changing and rebuilding it)
- Part 2 – How a native gem is loaded
- Part 3 – How the files get packaged so that the native extension is built during gem installation
- Part 4 – Understanding the Development Makefile
- Part 5 – The Ruby C API/ Interface
- Part 6 – Benchmarking relative performance
Background
Documenting code in Ruby land is quite simple with tools like rdoc or YARD. We can also use rdoc for documenting our native code but there are a few special things that we need to do. In this post, let’s look at that and why we need it.
Generating the documentation locally
Just go to the root directory of your gem and type rdoc to generate the documents. Then, open doc/index.html in your browser to see what we get.
$ rdoc
Parsing sources...
100% [17/17] perf/benchmark.rb
Generating Darkfish format into d:/projects/github/gems/fast-polylines/src/fast-polylines/doc...
Files: 17
Classes: 0 (0 undocumented)
Modules: 3 (2 undocumented)
Constants: 3 (3 undocumented)
Attributes: 0 (0 undocumented)
Methods: 5 (0 undocumented)
Total: 11 (5 undocumented)
54.55% documented
Elapsed: 0.6s
The picture below shows what the page looks like and I have annotated a few bits to discuss further.

Let’s look at three items:
- Module documentation
- Constant documentation (version) – we’ll look at this last
- Methods documentation
Module documentation
If you look through the Ruby files, you will see that the module is not documented anywhere. But if you look at the C code in ext/fast_polylines.c, you will find this block at the top.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/**
* Document-module: FastPolylines
*
* Implementation of the [Google polyline algorithm](https://code.google.com/apis/maps/documentation/utilities/polylinealgorithm.html).
*
* Install it with `gem install fast-polylines`, and then:
*
* require "fast_polylines"
*
* FastPolylines.encode([[38.5, -120.2], [40.7, -120.95], [43.252, -126.453]])
* # "_p~iF~ps|U_ulLnnqC_mqNvxq`@"
*
* FastPolylines.decode("_p~iF~ps|U_ulLnnqC_mqNvxq`@")
* # [[38.5, -120.2], [40.7, -120.95], [43.252, -126.453]]
*
* You can set an arbitrary precision for your coordinates to be encoded/decoded. It may be from 1
* to 13 decimal digits. However, 13 may be too much.
*
* [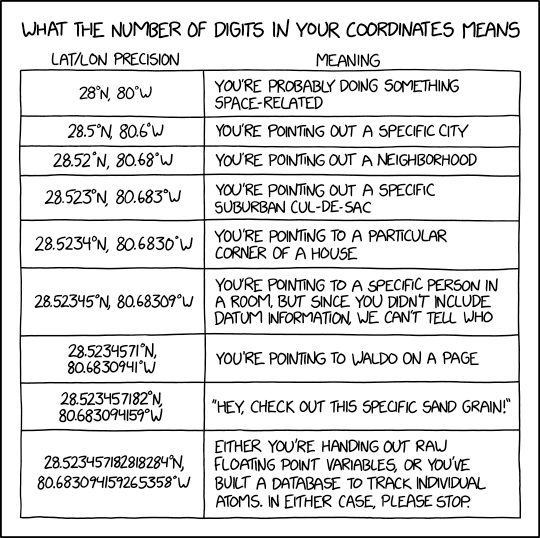](https://www.explainxkcd.com/wiki/index.php/2170:_Coordinate_Precision)
*/
Since this comment block starts with /**, it will be read by rdoc and processed. The special information is on the next line where we instruct rdoc that the following documentation is for a module called FastPolylines by saying: Document-module: FastPolylines. This block gets transformed into the documentation block (1) in the picture above.
As outlined in the documentation guide a code block needs to be preceded by and followed by a blank line. This is how the code samples get translated into highlighted code in the HTML.
Method documentation
Documenting methods is similar but there are a few more things to know. There are numerous methods in the C source code file, so how does the parser know which methods need to be extracted and which do not?
As highlighted in the parser documentation, it looks for the standard patterns that you find in extensions: rb_define_class, rb_define_method and so on. It tries to find the corresponding C source for the methods and extract comments. In the case of this extension, the Init_fast_polylines method does things like rb_define_module(“FastPolylines”)@ followed by using rb_define_module_function twice, once for decode and once for encode. For exmaple, we did this:
rb_define_module_function(mFastPolylines, "decode", rb_FastPolylines__decode, -1);In Part 5: The Ruby C API/ Interface, we looked at how this function defines rb_FastPolylines__decode as the method that provides the implementation for FastPolylines.decode in C. The parser then uses the comments block before the rb_FastPolylines__decode to provide the documentation for the FastPolylines.decode method, directly from the C source code file. If the code block comes directly above the named method, we don’t need to add Document-method: method_name since the RDoc C parser will put the pieces together. Note that the comment block needs to start with /** and before the named method in the C source.
1
2
3
4
5
6
7
8
/**
* call-seq:
* FastPolylines.decode(polyline, precision = 5) -> [[lat, lng], ...]
*
* Decode a polyline to a list of coordinates (lat, lng tuples). You may
* set an arbitrary coordinate precision, however, it **must match** the precision
* that was used for encoding.
*/
The other special thing you notice is the word call-seq which is needed in the comments block. Again, we explained that when defined the module function, we explained how the final argument is used. When it is -1, the function will be called as VALUE func(int argc, VALUE *argv, VALUE obj). The Ruby interpreter will call it with argc – the number of arguments, argv – a C array of the arguments and obj – the receiver object from Ruby. The document parser cannot understand the actual parameters for this method since it’s just called with argc and argv. The call-seq allows us to specify the actual calling sequence for this method so that it’s shown in the documentation.
The line shown after the call-seq is extracted to show the parameters and the return values. You can define multiple forms on subsequent lines as shown in the C parser documentation and the guide for documenting C source code files.
Version
Finally, the constant VERSION is the easiest. It’s picked up from the Ruby source code in lib/fast_polylines/version.rb and as you can see, it seamlessly coexists with the documentation that came from the C code.
Links and References
Much of the post here is based on information from this page about the RDoc C code Parser and the documentation guide for RDoc
Looking ahead
That brings us to the end of Part 7. If you have any comments, please feel free to leave them below.